
Рассмотрев ранее, как можно создавать PDF-документ, разными способами: и онлайн, и оффлайн и даже средствами Microsoft Office, пришло время рассказать, как произвести обратное действие.
Рассмотрим, как вытащить из PDF-документа текст, так чтобы можно было потом его редактировать в Word и подобных ему текстовых редакторах. То есть, попросту говоря, будем конвертировать PDF-файлы в Word.
- Adobe Reader и аналоги
- Система оптического распознавания текста (OCR)
- Онлайн-сервисы для конвертирования PDF-файлов
- Резюмируем
- Копируем текст из PDF файла в Word стандартным способом
- Копируем текст из PDF файла в Word с помощью ABBYY FineReader
- Копируем текст из PDF файла в Word c помощью конвертера
- Копируем текст из PDF файла в Word с помощью онлайн конвертеров
- Популярные средства распознавания текста
- Free Online OCR
- Распознавание текста с картинки в OneNote
- Видео — Переносим текст с фотографии в Word
- Распознавание текста с камеры мобильного устройства
- Видео — Как распознавать текст с картинки, фотографии или PDF файла
Adobe Reader и аналоги
Самый простой, быстрый и бесплатный вариант:
Открываем нужный PDF-документ в Adobe Reader. Заходим в меню Редактировать, потом выбираем команду “Копировать файл в буфер обмена”
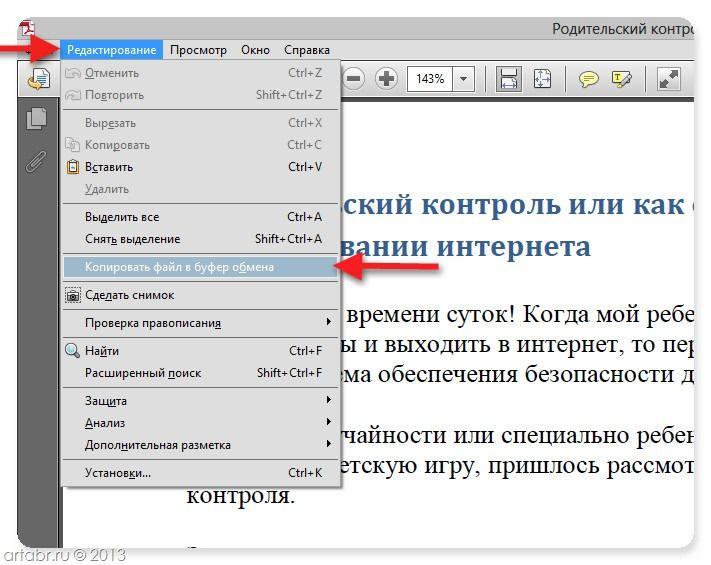
А дальше, стандартные действия: открываем Word, создаем новый документ и нажимаем кнопку Вставить или воспользуемся быстрыми клавишами (Ctrl+V).
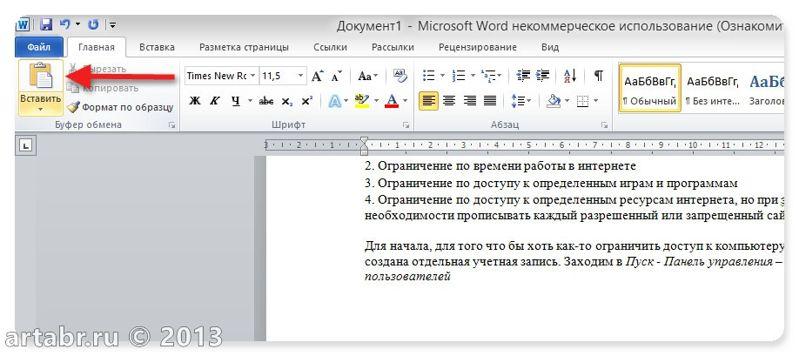
Все, можно спокойно редактировать полученный текст.
Если вам, все таки, во что бы то ни стало нужно извлечь изображение из PDF-документа, чтобы не использовать какие-нибудь программы, сделайте скриншот с экрана на котором открыт PDF-файл, из которого вы скопировали текст, но не получилось скопировать картинку.
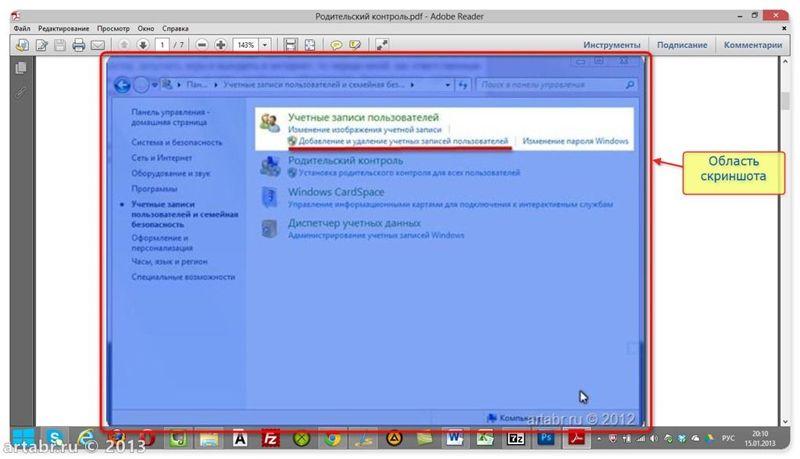
И полученное изображение вставьте в Word. Должно получиться вот так:
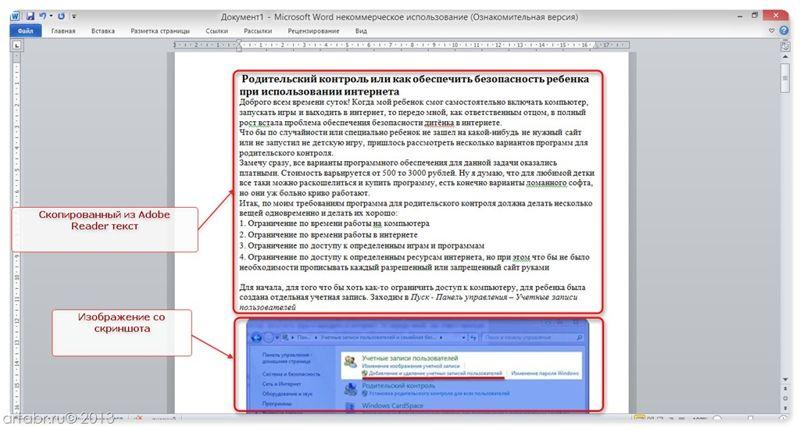
Понятно, что качество изображения будет оставлять желать лучшего, но как запасной вариант вполне подойдет.
В других просмотрщиках нужно будет сделать несколько иное действие.
Вот так в Foxit Reader (меню инструменты –> команда Выделить текст):
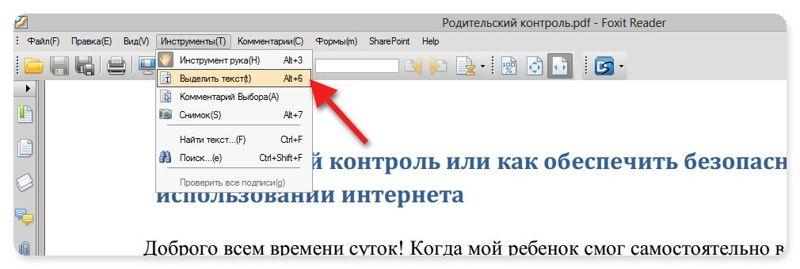
А вот так в PDF-XChange Viewer (меню Инструменты –> Основные –> Выделение):
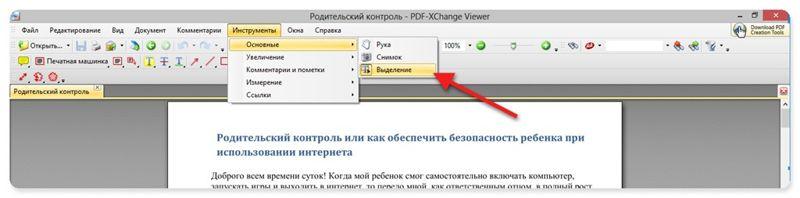
Затем выделяем нужный текст и производим стандартные действия с буфером обмена, для тех кто не догадался: Копировать (Ctrl+C) и в Word — Вставить (Ctrl+V).
Система оптического распознавания текста (OCR)
При всей прелести этой методики у нее есть недостаток. Конвертировать PDF в Word не получиться, если PDF-документ создан сканированием с бумажного носителя или защищен от редактирования.
Поэтому будем использовать другой метод. А имено, с помощью специальной программы оптического распознавания текста.
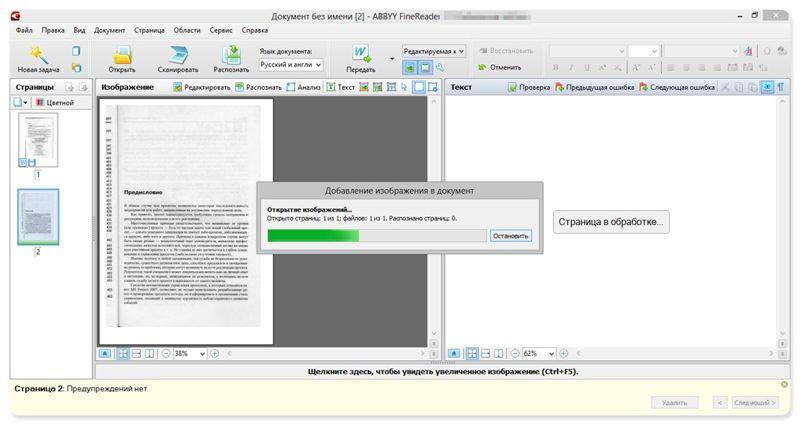
Программа называется ABBYY FineReader и, к сожалению, является платной. Но зато функционал этой программы позволит перекрыть любые требования по созданию и конвертированию PDF-файлов.
Вот, например, имеем отсканированный текст в PDF формате
Запускаем ABBYY FineReader и в стартовом окне выбираем Файл в Microsoft Word
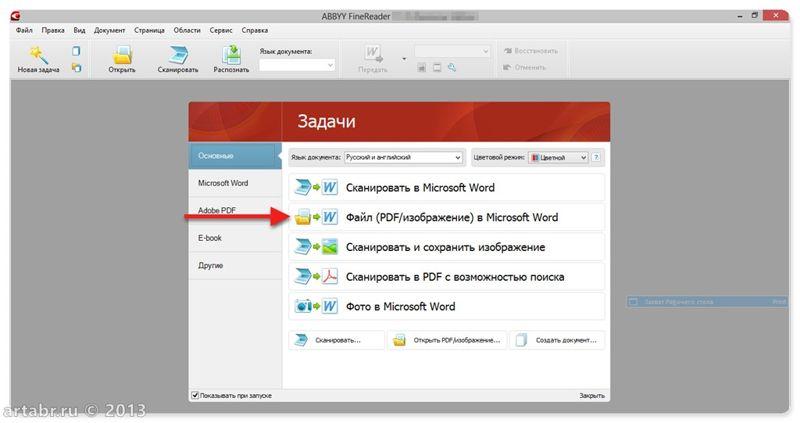
И все! Система сама распознает текст и отправляет его в Word

Онлайн-сервисы для конвертирования PDF-файлов
Вариант с онлайн-сервисами я уже описывал, единственно, что могу добавить еще пару подобных сервисов:
И опять же, ни один из онлайн-сервисов не работает с изображениями, и если текст у вас отсканирован и сохранен в формате PDF, то ничего не получится. Необходимо будет рассматривать вариант OCR.
Резюмируем
Как обычно, самым удобным оказался платный вариант, но остальные имеют право на существование, потому что не каждый день требуется преобразовывать файлы PDF. А на один раз можно или скачать демо-версию или воспользоваться онлайн-сервисом.
Если нельзя, но сильно надо, то способ всегда найдется.
Да, и еще, если Вы знаете еще какой-нибудь способ преобразования PDF-файлов, напишите мне в комментариях.
Спасибо за внимание!
P.S. Лирическое отступление:
Сижу расстроенная, подходит мелкий брат, суёт конфетку, я ему говорю:
— Дима, у меня взрослые проблемы, и этим их не решить.
Через 5 минут приходит с бутылкой мартини и спрашивает:
— А этим?
* * *
Ребенок (2 года) в парке увидел близнецов. Долго и удивленно их разглядывал. Поворачивается к маме и с нажимом спрашивает:
— А где мой такой?!
* * *
Еду в трамвае. За моей спиной сидит девочка, лет пяти. Она у окна, а рядом её мама. Девочка:
— Мам, а мам, а зачем реклама на сидениях — хочешь, скажу? Ну, вот скажи, хочешь? Ты только спроси — я тебе сразу скажу, я все тебе объясню, расскажу. Ты знаешь, зачем это? Ну, чего ты молчишь? Ну, спроси меня, давай!!!
Мама не выдерживает:
— Ну и зачем?
— Чтоб дети в трамваях читали… А не задавали взрослым глупые вопросы





Вот такое искажение текста идет, если через буфер обмена
oaenoiaie .aaaeoi.; yeaeo.iiiay oaaeeoa; nenoaia oi.aaeaiey
aacaie aaiiuo; i.ia.aiia aiaeeca e ninoaaeaiey .anienaiee;
i.ia.aiia i.acaioaoee; a.aoe.aneee .aaaeoi.; i.ia.aiia ia-
neo.eaaiey oaen-iiaaia; naoaaia i.ia.aiiiia iaania.aiea:
yeaeo.iiiay ii.oa, eiiiu.oa.iua e oaeaeiioa.aioee e a..;
i.ia.aiiu ia.aaiaa; niaoeaeece.iaaiiua i.ia.aiiu oi.aa-
eai.aneie aayoaeuiinoe: aaaaiey aieoiaioia, eiio.iey ca en-
iieiaieai i.eeacia e a..
2 4 Eioaa.e.iaaiiue iaeao
Приветствую! В вашем случае есть масса вариантов. Это может быть и версия ридеров и офиса не подходит, и кодировка кривая или вообще файл защищен от копирования. Сложно что-то сказать-сделать когда файла перед глазами нет. Свяжитесь со мной по почте. Постараюсь помочь.
Скажите пожалуйста, я правильно понял если в документе установлен запрет на копирование, то я ничего сделать не смогу кроме как распознавать платной программой?
Да, правильно. Можно попробовать сломать, но проще распознать. Fine Reader имеет 30 дневный доступ бесплатный, думаю этого должно хватить чтобы распознать несколько файлов
Читайте также: Мегафон тариф для ватсапа
Привет, Артем!
Я пару раз пробовал конвертировать pdf в word онлайн, ну, что то не чего не получилось…
Смотрю, Артем ты не как не затачиваешь статьи под поисковые запросы.
Пишешь для тех, кто уже на сайте.
Вордстатом Яндекса вообще не пользуешься? 
То, что ты в keywords прописал «конвертировать pdf, pdf в word онлайн, как преобразовать pdf в word» на это же поисковики мало смотрят, если вообще смотрят. Хорошо, что в title прописал, но в тексте(я не говорю уж про заголовки) не где не встречается вообще ПРЯМОГО запроса НЕ РАЗУ!, и в description нет даже не прямого вхождения. ни в урл…
На него очень обращают внимание, после title.
Просто знаешь, вот пишешь интересно(у меня такого нет)), но не затачиваешь абсолютно… а внутренняя оптимизация, это самое главное.
Я сейчас некоторые Ларисины статьи с ходовыми запросами подгоняю по релевантности, с анализом в мегаиндексе и позиции по этим запросам значительно подрастают.
Не обижайся за …. , ну ты понял, просто такие информационные статьи должны быть в топе.
Посмотри у Александра Бобрина на сайте asbseo.ru есть бесплатный курс «Как раскрутить блог», там коротко, но понятно обо всем говориться. рекомендую.
Привет, Александр! Отвечаю по порядку:
Вордстатом пользуюсь и адворксом то же пользусь. Это раз.
Скажи, а на что тогда поисковики смотрят если не на ключевики? Как раз на дескрипшинос они мало смотрят, потому как если description не прописан, то поисковик сам подбирает снипет. А ключевики — это как раз то на что ПС смотрят в первую очередь. Это два.
То что, статья была не релевантна ключевикам — это я согласен, но я ее писал на заре своего блоговодства почти год назад, сейчас поправил немного. Это три.
Даже при всех ошибках, эта статья сидит в топ 10 Яндекса. Набери в Яше «как конвертировать pdf в word» статья будет на 6-7 месте. Правда гоша не радует, но это дело техники. Это четыре.
Ну и пять, у меня с СЕО вообще проблема — я сначала статьи пишу, а потом ключевики под них подбираю.
Вот как-то так.
PS Бобрина, Борисова и многих других читал и изучал. Но Сео — это не мое. Вот еще момент, пару месяцев назад всем известный Дмитрий Ктонановенького попал под фильтры, а знаешь почему? За переоптимизацию статей! Так что, я за человекообразные статьи, а не заточенные под ПС.
Точно, Артем, смотрю у Ларисы статьи есть с релевантностью 12-30%, а в топе…
Я наверное ерундой занимаюсь, что у всех её статей сейчас релевантность повышаю?
Тоже под фильтр бы не попасть.. 
Но у меня тоже редко получается 100%, обычно 70-90%. Это наверное пойдет?
Ну да, что я спрашиваю, ты же с сео не дружишь.
70-90% релевантности говорит, только о том, что наполнение статьи ключевыми словами составляет 70-90% от нормы, вот и все.
Знаешь, я у одного блогера прочитал, насчет проверки текста на тошнотность: «Проверку на тошнотность делаю на «глазок», если самого не тошнит от переизбытка ключевиков, значит и ПСам подойдет» Это я почти цитирую… Так вот, про релевантность тоже самое могу сказать, ПС становятся с каждым апдейтом все «чудесатее и чудесатее» и какой алгоритм проверки будут использовать никогда не угадаешь. Так что пиши ориентируясь на людей. Я так думаю (с)
добрый день, подскажите пожалуйста как Вы сделали такой вид статей? Или это так и было уже в готовом виде шаблона?
Добрый день! В принципе все было в шаблоне, я только немного допили. Хотел уточнить: а какой такой вид?
У меня двуязычный текст, английскую часть копирует без проблем, но русские вставки — вместо них бред латинскими буквами! Как исправить?
Пробуйте изменить шрифт, скорее всего в документе используется шрифт, который не поддерживает кириллицу.
Формат PDF довольно часто используется для публикации разного рода электронных документов. В PDF публикуются научные работы, рефераты, книги, журналы и многое другие.
Сталкиваясь с документом в PDF формате, пользователи часто не знают, как скопировать текст в Ворд. Если у вас также возникла подобная проблема, то наша статья должна вам помочь. Здесь вы узнаете 4 способа, как скопировать текст из PDF в Ворд.
Копируем текст из PDF файла в Word стандартным способом
Самый простой способ скопировать текст из PDF в Ворд это обычное копирование, которым вы пользуетесь постоянно. Откройте ваш PDF файл в любой программе для просмотра PDF файлов (например, можно использовать Adobe Reader), выделите нужную часть текста, кликните по ней правой кнопкой мышки и выберите пункт «Копировать».
Читайте также: Как узнать пароль от роутера zte
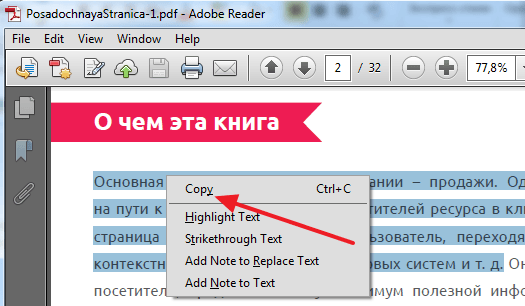
Также вы можете скопировать текст с помощью комбинации клавиш CTRL-C. После копирования текст можно вставить в Ворд или любой другой текстовый редактор.
К сожалению, данный способ копирования текста далеко не всегда подходит. PDF файл может быть защищен от копирования, тогда вам не удастся выполнить копирование текста. Также в PDF документе могут быть таблицы или картинки, которые нельзя просто так скопировать. Если вы столкнулись с подобной проблемой, то следующие способы копирования текста из ПДФ должны вам помочь.
Копируем текст из PDF файла в Word с помощью ABBYY FineReader
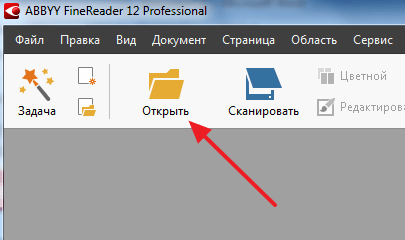
ABBYY FineReader это программа для распознавания текста. Обычно данную программу используют для распознавания текста на отсканированных изображениях. Но, с помощью ABBYY FineReader можно распознавать и PDF файлы. Для этого откройте ABBYY FineReader, нажмите на кнопку «Открыть» и выберите нужный вам PDF файл.
После того как программа закончит распознавание текста нажмите на кнопку «Передать в Word».
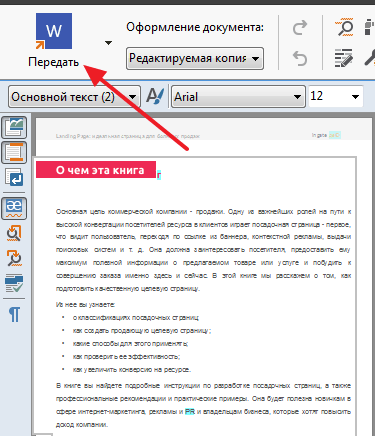
После этого перед вами должен открыться документ Ворд с текстом из вашего PDF файла.
Копируем текст из PDF файла в Word c помощью конвертера
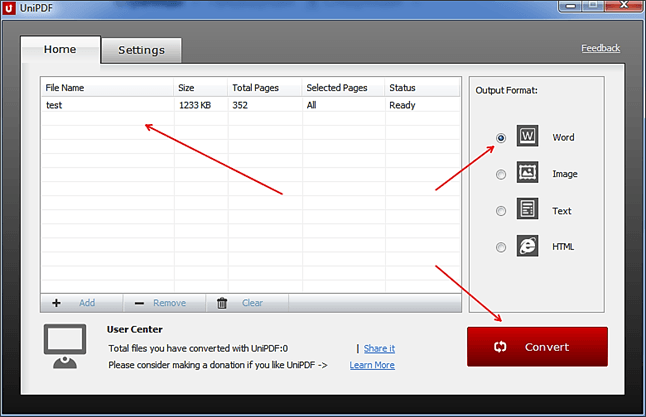
Если у вас нет возможности воспользоваться программой ABBYY FineReader, то можно прибегнуть к программам-конвертерам. Такие программы позволят конвертировать PDF документ в Word файл. Например, можно использовать бесплатную программу UniPDF.
Для того чтобы сконвертировать PDF документ в Word файл с помощью UniPDF вам нужно просто открыть программу, добавить в нее нужный PDF файл, выбрать конвертацию в Word и нажать на кнопку «Convert».
Копируем текст из PDF файла в Word с помощью онлайн конвертеров
Также существуют онлайн конвертеры, которые позволяют сконвертировать PDF файл в Word файл. Обычно такие онлайн конвертеры работают хуже, чем специализированные программы, но они позволят скопировать текст из PDF в Ворд без установки дополнительного софта. Поэтому их также нужно упомянуть.
Использовать такие конвертеры довольно просто. Все что вам нужно сделать, это загрузить файл и нажать на кнопку «Конвертировать». А после завершения конвертации нужно будет скачать файл обратно.
Популярные онлайн конвертеры из PDF в Word:
Навык извлечения текста из изображений — один из очень важных при работе с компьютером. На самом деле это очень просто, однако не многие знают, как это сделать.
Как с фото перенести текст в Ворд
Популярные средства распознавания текста
Существует множество как онлайн сервисов, так и десктопных программ, которые позволяют распознать текст практически из любого графического файла. Самый известный и совершенный инструмент — ABBYY Finereader. Эта программа обладает массой преимуществ, однако, работает она преимущественно платно. Есть у нее и пробные версии, но они сильно ограничивают пользователей по объему изображений и требуют обязательной регистрации.
Ниже будут рассмотрены более доступные, бесплатные и простые средства для распознавания текста с изображений.
ПриложениеИзображениеОписаниеImage to Text Converter  Сервис позволяет конвертировать отсканированные фотографии или PDF файлы в формат Word или TXT. Базовый OCR инструмент, не требующий даже регистрации на сайте Free Online OCR
Сервис позволяет конвертировать отсканированные фотографии или PDF файлы в формат Word или TXT. Базовый OCR инструмент, не требующий даже регистрации на сайте Free Online OCR  Это бесплатное онлайн программное обеспечение, позволяющее конвертировать изображения в редактируемые Word, Text, Excel форматы Text Fairy (OCR Text Scanner)
Это бесплатное онлайн программное обеспечение, позволяющее конвертировать изображения в редактируемые Word, Text, Excel форматы Text Fairy (OCR Text Scanner)  Сервис для мобильных устройств. Среди доступных функций: конвертирование картинки в текст, редактирование изображения для лучшего распознавания, редактирование полученного текста, преобразование изображений в PDF. Доступно более 50 языков. Бесплатно и без рекламы OneNoteОдна из стандартных программ офисного пакета Windows. Предназначена для создания и хранения заметок. Не является исключительно средством по распознаванию текста с изображения, однако имеет такую функцию Office LensПрограммное обеспечение от Microsoft для мобильных устройств. Предназначено для захвата изображений с помощью камеры вашего телефона и извлечения текста
Сервис для мобильных устройств. Среди доступных функций: конвертирование картинки в текст, редактирование изображения для лучшего распознавания, редактирование полученного текста, преобразование изображений в PDF. Доступно более 50 языков. Бесплатно и без рекламы OneNoteОдна из стандартных программ офисного пакета Windows. Предназначена для создания и хранения заметок. Не является исключительно средством по распознаванию текста с изображения, однако имеет такую функцию Office LensПрограммное обеспечение от Microsoft для мобильных устройств. Предназначено для захвата изображений с помощью камеры вашего телефона и извлечения текста
Free Online OCR
OnlineOCR.net поддерживает 46 языков распознавания среди которых помимо основных: английского, русского, немецкого и французского и других европейских языков, есть даже китайский, македонский и албанский.
Сервис может обрабатывать следующие форматы изображений:
- PDF (все типы файлов PDF, включая многостраничные);
- TIF/TIFF (поддерживается многостраничное TIFF);
- JPEG/JPG;
- BMP;
- PCX;
- PNG;
- GIF;
Также могут быть загружены ZIP-файлы, содержащие вышеуказанные типы файлов.
 Виды форматов изображений
Виды форматов изображений
Имейте в виду, что сервис обрабатывает далеко не все изображение. Второе важное условие — его размер. Он не должен превышать 200 Мб. Это касается многостраничных PDF, но если ваша цель — распознать текст с одного или двух изображений — вам не придется об этом беспокоиться.
Примечание! Качество изображения является одним из наиболее важных факторов, повышающих эффективность распознавания. Для обработки лучше всего использовать фотографии, разрешение которых не меньше 200-400 точек на дюйм для входных изображений.
Сервис предоставляет возможность конвертировать распознанный текст в 5 форматов вывода:
- Adobe PDF;
- Microsoft Word;
- Microsoft Excel;
- RTF;
- Обычный текстовый документ.
Читайте также: Невозможно открыть страницу андроид гугл на телефоне
Шаг 1. Перейдите на сайт онлайн сервиса. Нажмите на кнопку “Select file…”, чтобы открыть изображение с вашего компьютера.
 Переходим на сайт онлайн сервиса
Переходим на сайт онлайн сервиса
Шаг 2. Выберите необходимый вам язык и подходящий формат.
 Выбираем необходимый вам язык и подходящий формат
Выбираем необходимый вам язык и подходящий формат
Шаг 3. Нажмите на кнопку «Convert».
 Нажимаем на кнопку «Convert»
Нажимаем на кнопку «Convert»
Вы можете видеть результат распознавания текста. В качестве исходного файла использовался скриншот фрагмента этой статьи. Поскольку в качестве языка распознавания был выбран русский, система не смогла корректно распознать такие слова как Free, TIFF, ZIP и другие.
Распознавание текста с картинки в OneNote
Стандартные программы офисного пакета Microsoft так же могут быть использованы для достижения вашей цели. Если вы не знали, в OneNote есть встроенное ПО для оптического распознавания печатных символов. Использовать его очень просто, вы можете убедиться в этом, продолжив чтение.
Шаг 1. Откройте свое изображение в любом средстве просмотра фотографий. Нажмите на кнопку печать.
 Открываем фото и нажимаем печать
Открываем фото и нажимаем печать
Шаг 2. В параметрах печати измените ваш принтер на программу OneNote.
 Меняем принтер на программу OneNote
Меняем принтер на программу OneNote
Шаг 3. Программа загрузится автоматически. В первую очередь выберите место расположения фотографии. Лучше всего использовать пустую страницу записной книжки, хотя это не принципиально.
 Выбираем место расположение фотографии
Выбираем место расположение фотографии
Шаг 4. Теперь вы должны увидеть свое изображение вставленным в пустую страницу вашей записной книжки. Щелкните мышью по области изображения. В разделе «Поиск текста в рисунках» выберите русский, или любой другой в зависимости от текста, который необходимо распознать.
 В разделе «Поиск текста в рисунках» выбираем необходимый язык
В разделе «Поиск текста в рисунках» выбираем необходимый язык
Шаг 5. Изменив язык распознавания, снова щелкните по изображению и воспользуйтесь одной из функций копирования текста.
 Копируем текст
Копируем текст
Шаг 6. Теперь вам нужно только лишь вставить выбранный текст в пустую область, и, если в этом будет необходимость, отредактировать его. Узнайте, как правильно отредактировать PDF документ в статье — «Как отредактировать PDF документ»
Примечание! Текст в OneNote распознается и копируется именно в том порядке, в котором он расположен на изображении. Если оно представляет собой несколько столбцов, вы получите несколько коротких строк, которые будут идти одна за другой.
Видео — Переносим текст с фотографии в Word
Распознавание текста с камеры мобильного устройства
Несколько лет назад компания Microsoft выпустила Office Lens, приложение для фотографирования и сканирования файлов для iPhone и Android. Приложение может сканировать изображение, полученное с камеры или из галереи, и преобразовывать изображение в текст. Затем текст можно экспортировать и открыть в приложении MS Office или MS PowerPoint, если они установлены на вашем устройстве. Текст также можно экспортировать в OneNote, сохранить в качестве файла в OneDrive или отправить в приложение Mail.
Шаг 1. Найдите в Play Market приложение Office Lens, установите его на свое мобильное устройство и запустите.
 Устанавливаем приложение Office Lens
Устанавливаем приложение Office Lens
Шаг 2. Во время первого открытия программа проведет краткое обучение по его использованию, после чего откроется окно камеры. Наведите ее на текст, так, чтобы он попал в специальную рамку. Если вы приглядитесь к скриншоту, вы увидите едва заметный прямоугольник (на самом деле он намного ярче). Убедитесь, что текст попадает в это поле и нажмите на белую кнопку внизу. Вы можете включить вспышку, если света недостаточно, чтобы улучшить сканирование.
 Наводим камеру на текст
Наводим камеру на текст
Шаг 3. В окне предварительного просмотра вы можете повернуть или обрезать изображение, в общем, отредактировать его. После чего нажмите на кнопку «Готово» в правом нижнем углу.
 Редактируем изображение и нажимаем кнопку «Готово»
Редактируем изображение и нажимаем кнопку «Готово»
Шаг 4. В списке доступных программ для вывода информации выберите Word. Приложение начнет обрабатывать ваш файл. Как только процесс завершится, вы сможете открыть текстовый документ.
 В списке доступных программ для вывода информации выбираем Word
В списке доступных программ для вывода информации выбираем Word  Приложение обрабатывает файл
Приложение обрабатывает файл
Шаг 5. Программа работает отлично, а главное быстро и с минимальным количеством возможных опечаток (в нашем случае их и вовсе не было, поскольку выбранное изображение — весьма простое).
 Результат работы приложения
Результат работы приложения
Приложение имеет три режима:
- фото (для сканирования фотографий);
- документ для преобразования изображения в текст;
- режим доски, который позволяет захватывать изображение и делиться им с другими.
После сканирования документа вы можете экспортировать его в Word, PowerPoint, OneNote в виде файла PDF или отправить его в приложение Mail на iPhone.







